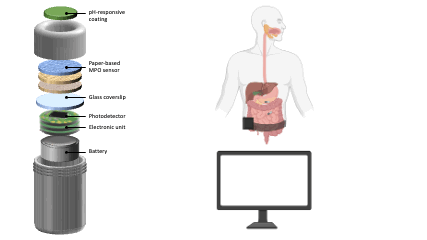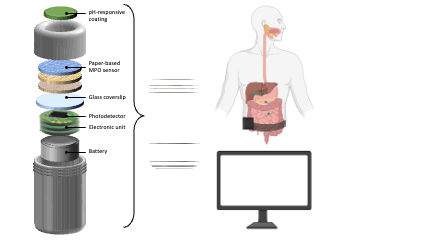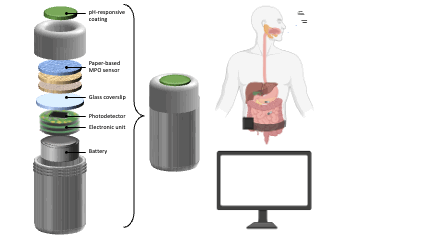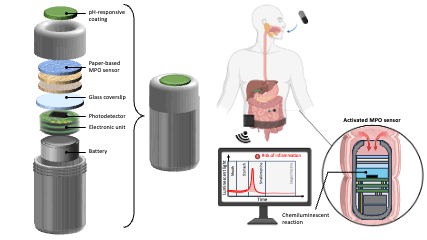
Impact of Injection-Based Delivery Parameters on Local Distribution Volume of Ethyl-Cellulose Ethanol Gel in Tissue and Tissue Mimicking Phantoms
https://www.embs.org/tbme/wp-content/uploads/sites/19/2024/04/TBME-00960-2023-Website_Image.jpg
789
444
IEEE Transactions on Biomedical Engineering (TBME)
//www.embs.org/tbme/wp-content/uploads/sites/19/2022/06/ieee-tbme-logo2x.png
Impact of Injection-Based Delivery Parameters on Local Distribution Volume of Ethyl-Cellulose Ethanol Gel in Tissue and Tissue Mimicking Phantoms
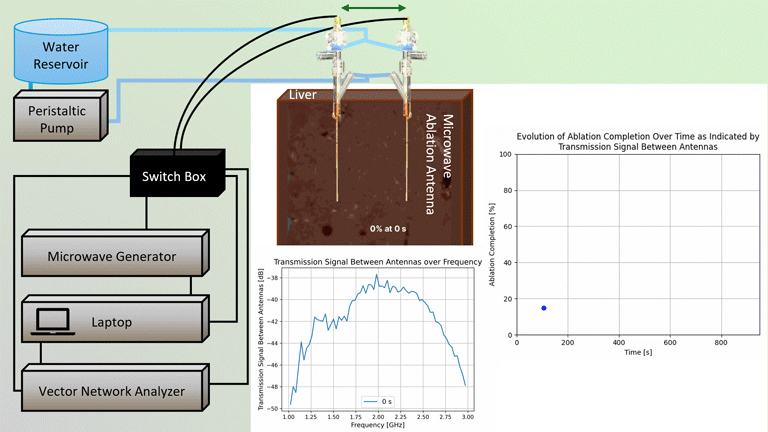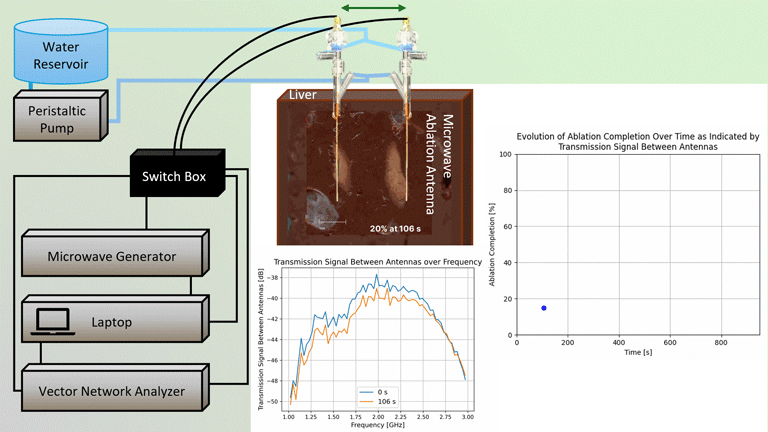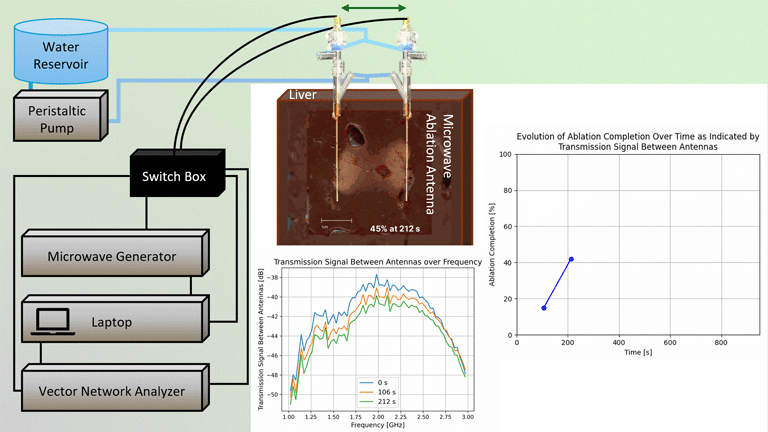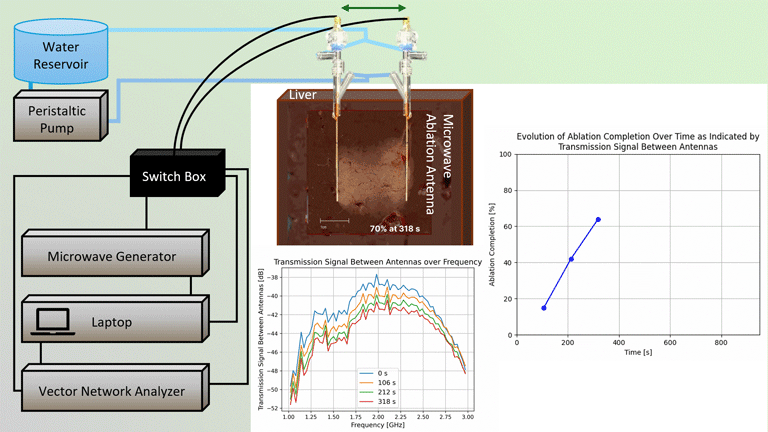
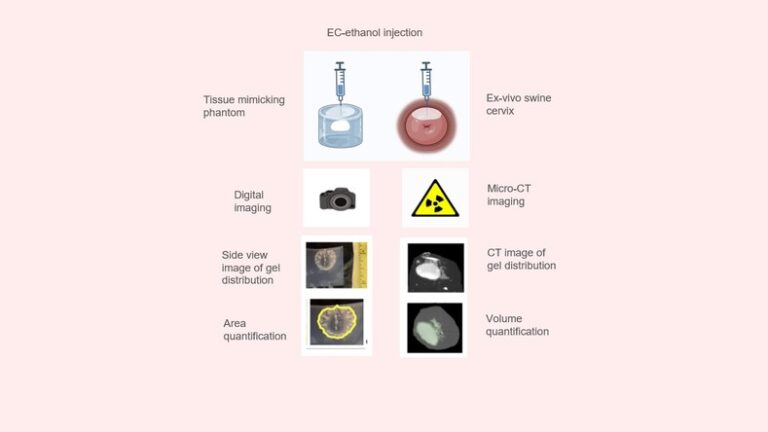
We explored the impact of injection-based parameters on resulting distribution of our ethanol gel at a scale relevant to human applications, particularly how to best deliver it into the cervix.
read more